Publications
A collection of my research work.
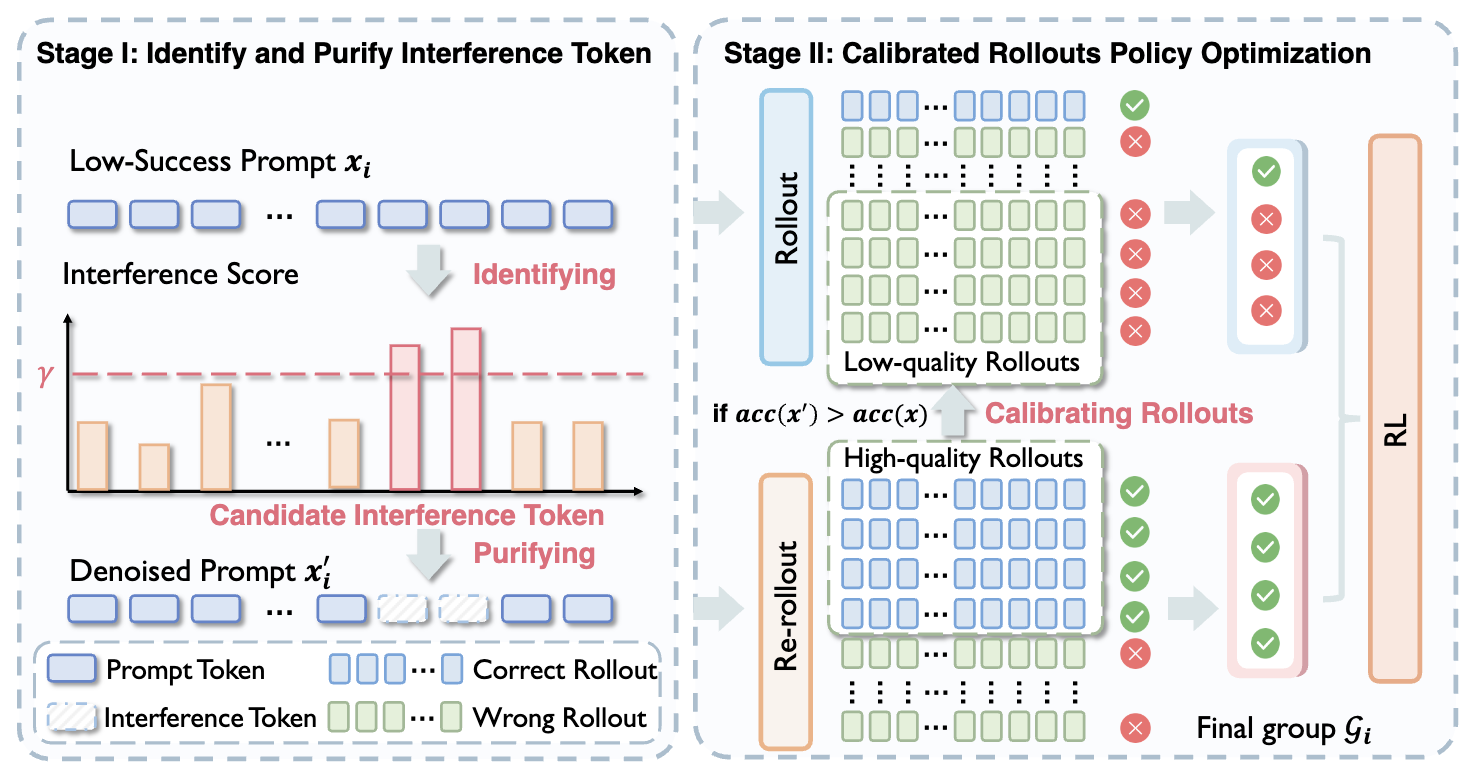
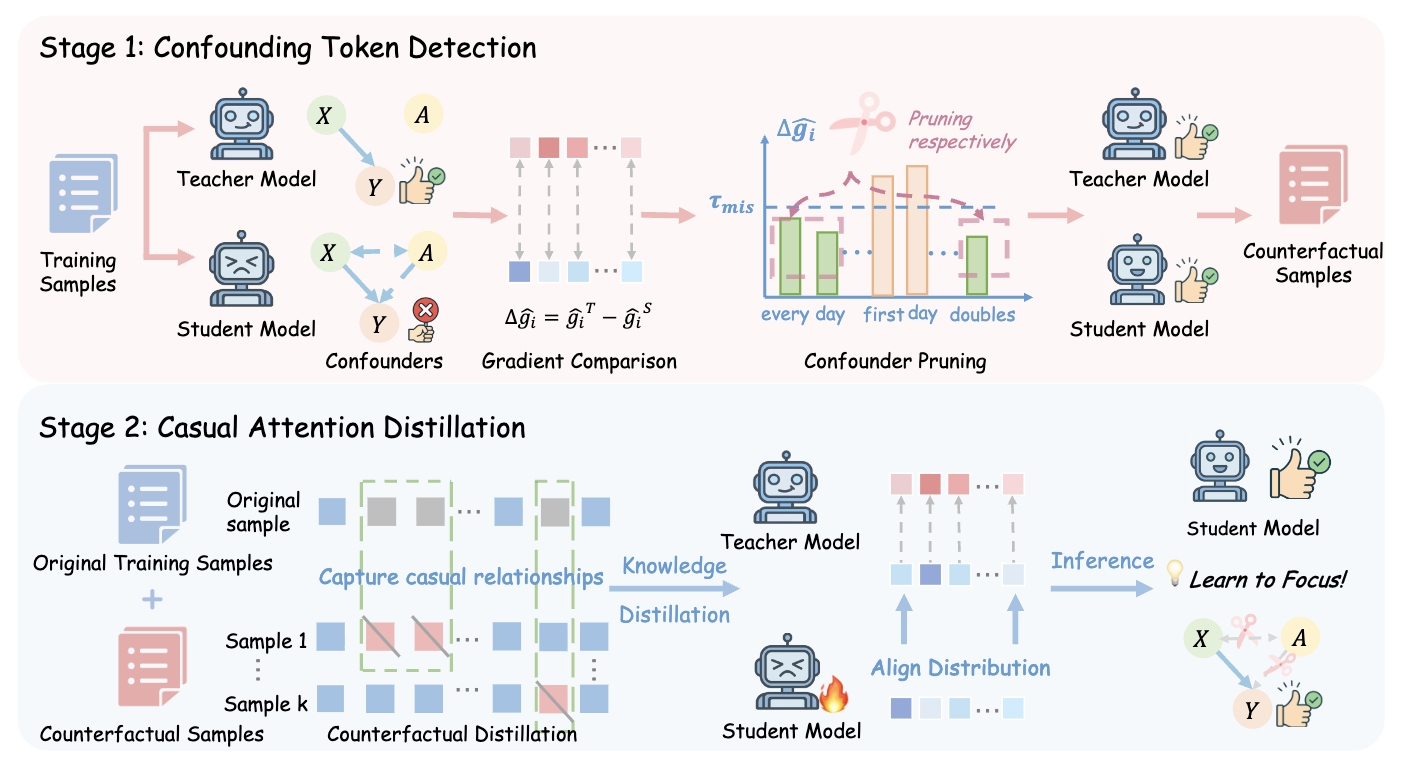
Learning to Focus: Causal Attention Distillation via Gradient-Guided Token Pruning
Yiju Guo, Wenkai Yang, Zexu Sun, Ning Ding, Zhiyuan Liu, Yankai Lin
NeurIPS 2025 Conference 2025
A framework to improve LLM reasoning by removing distracting tokens via causal attention distillation and gradient-guided pruning.
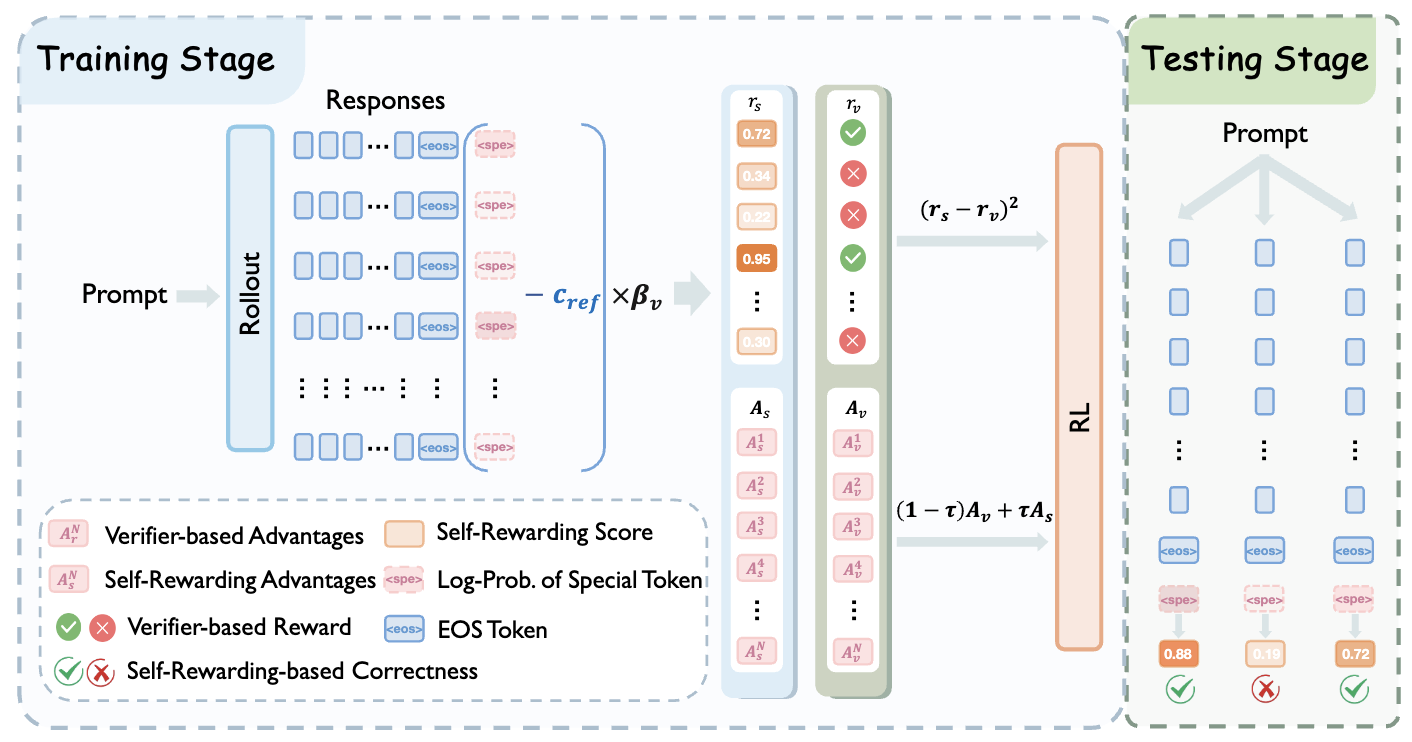
LaSeR: Reinforcement Learning with Last-Token Self-Rewarding
Wenkai Yang, Weijie Liu, Ruobing Xie, Yiju Guo, Lulu Wu, Saiyong Yang, Yankai Lin
ICLR 2026 Conference 2025
An efficient RL method that unifies reasoning and verification by utilizing the last-token probability as a self-rewarding signal.
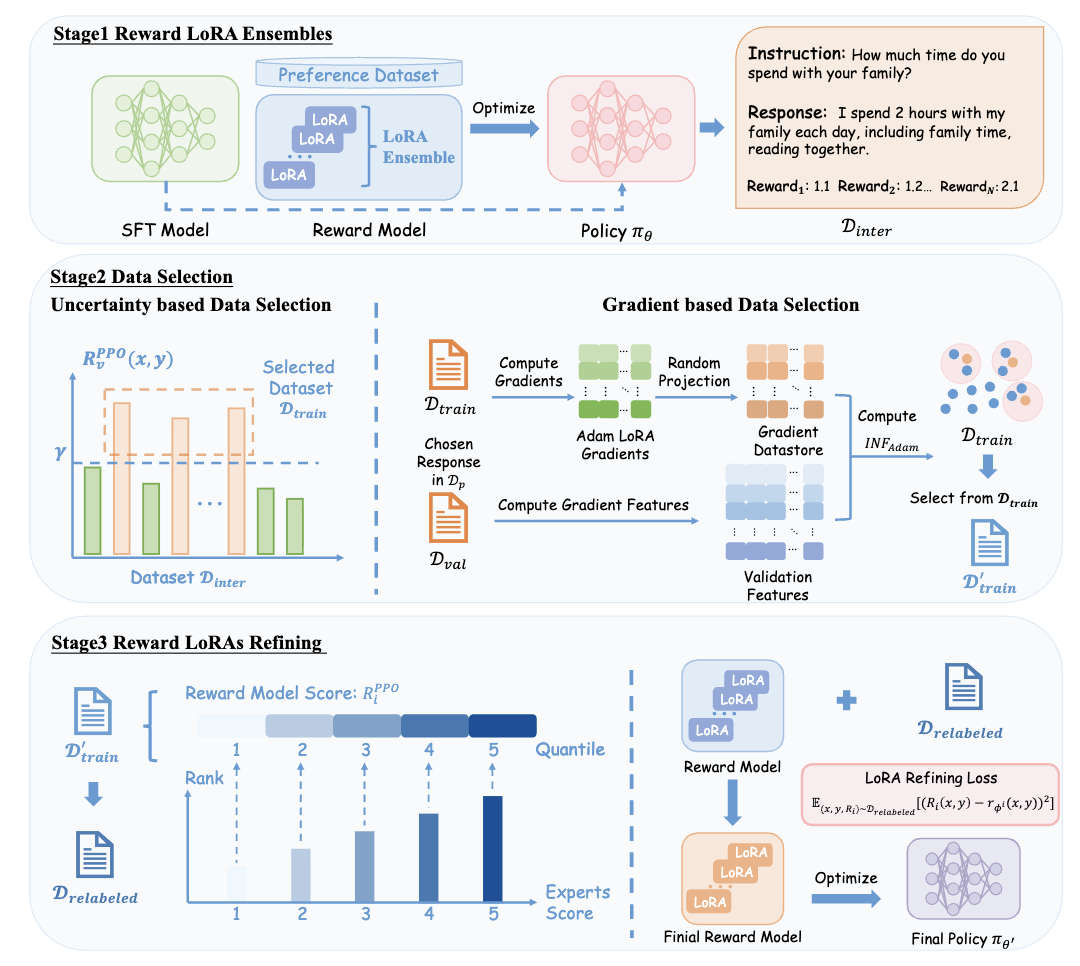
Uncertainty and influence aware reward model refinement for reinforcement learning from human feedback
Zexu Sun, Yiju Guo, Yankai Lin, Xu Chen, Qi Qi, Xing Tang, Ji-Rong Wen
ICLR 2025 Conference 2025
An uncertainty-aware data augmentation method to refine reward models in RLHF without expensive human annotation.
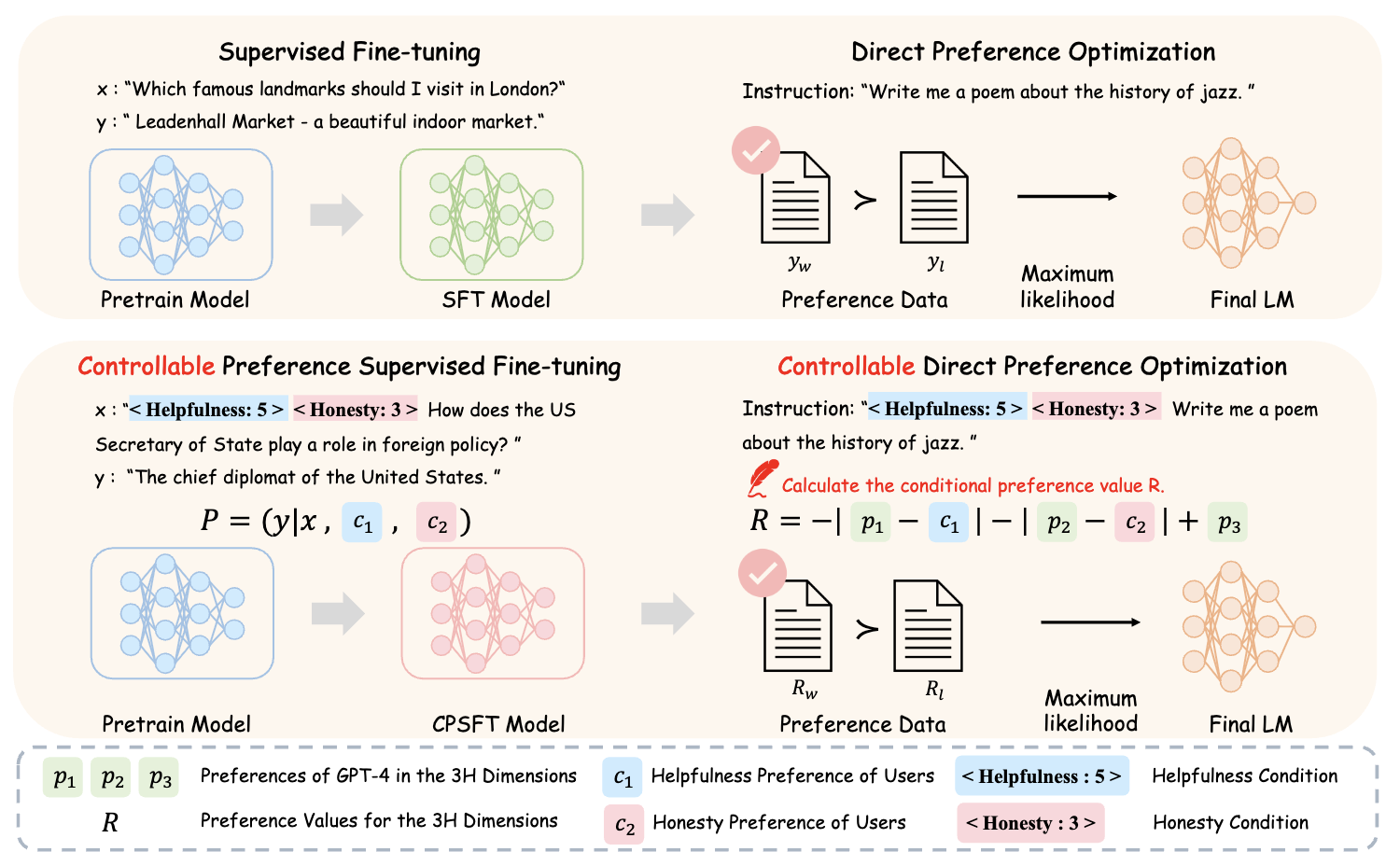
Controllable preference optimization: Toward controllable multi-objective alignment
Yiju Guo, Ganqu Cui, Lifan Yuan, Ning Ding, Zexu Sun, Bowen Sun, Huimin Chen, Ruobing Xie, Jie Zhou, Yankai Lin, others
EMNLP 2024 main conference 2024
A multi-objective alignment method that explicitly controls preference scores to balance helpfulness, honesty, and harmlessness.
Amvae: Asymmetric multimodal variational autoencoder for multi-view representation
Wen Youpeng, Lin Hongxiang, Guo Yiju, Zhao Liang
International Conference on Artificial Neural Networks 2021
A variational autoencoder framework for learning representations from asymmetric multimodal data.